Crafting with Karpenter - investigating Node Auto-Provisioning

Introduction
Recently a new preview feature to AKS has been introduced. Based on the open source Karpenter from AWS. Node Autoprovisioning (NAP) enhances the default Node Scaler. Rather than having to decide ahead of time potential requirements of CPU, Memory for your workloads. NAP decides the node requirements for pending resources.
Pre-Reqs
Before spinning up a cluster to test you need to enable enable to aks-preview extension and register the NodeAutoProvisiongPreview feature.
az extension add --name aks-preview
az feature register --namespace "Microsoft.ContainerService" --name "NodeAutoProvisioningPreview"
Registering a new feature can take a couple of minutes to complete you can check the status of the registration with the command
az feature show --namespace "Microsoft.ContainerService" --name "NodeAutoProvisioningPreview"
Once the feature has been registered also refresh the Container Service provider.
az provider register --namespace Microsoft.ContainerService
Limitations
- NAP can only be enabled on new clusters at creation
- Once running, it is not possible to stop clusters/nodepools using NAP.
- Windows and Azure Linux node pools are currently not supported
- Kubelet configuration is not supported.
Deploying AKS with NAP
To enable NAP when creating a new cluster, add the following flag --node-provisioning-mode to Auto.
To use the cilium network dataplane we are also adding the flags for --network-plugin-mode, --network-plugin and --network-dataplane. For testing purposes, I am also tainting the system node pool to ensure only critical workloads run on it.
az group create --name rg-springclean-nap-uks `
--location uksouth
az aks create --name aks-springclean-nap-uks `
--resource-group rg-springclean-nap-uks `
--node-provisioning-mode Auto `
--network-plugin azure `
--network-plugin-mode overlay `
--network-dataplane cilium `
--nodepool-taints CriticalAddonsOnly=true:NoSchedule

Once run your new AKS cluster will be deployed and running with Node Autoprovisioning running.
Testing
Now that the cluster is running we can start to play and test the new Node Autoprovisioning feature.
Checking to see what nodes we have in the cluster:
kubectl get nodes -o wide

Checking state of all deployed pods within the cluster:
kubectl get pod -A -o wide
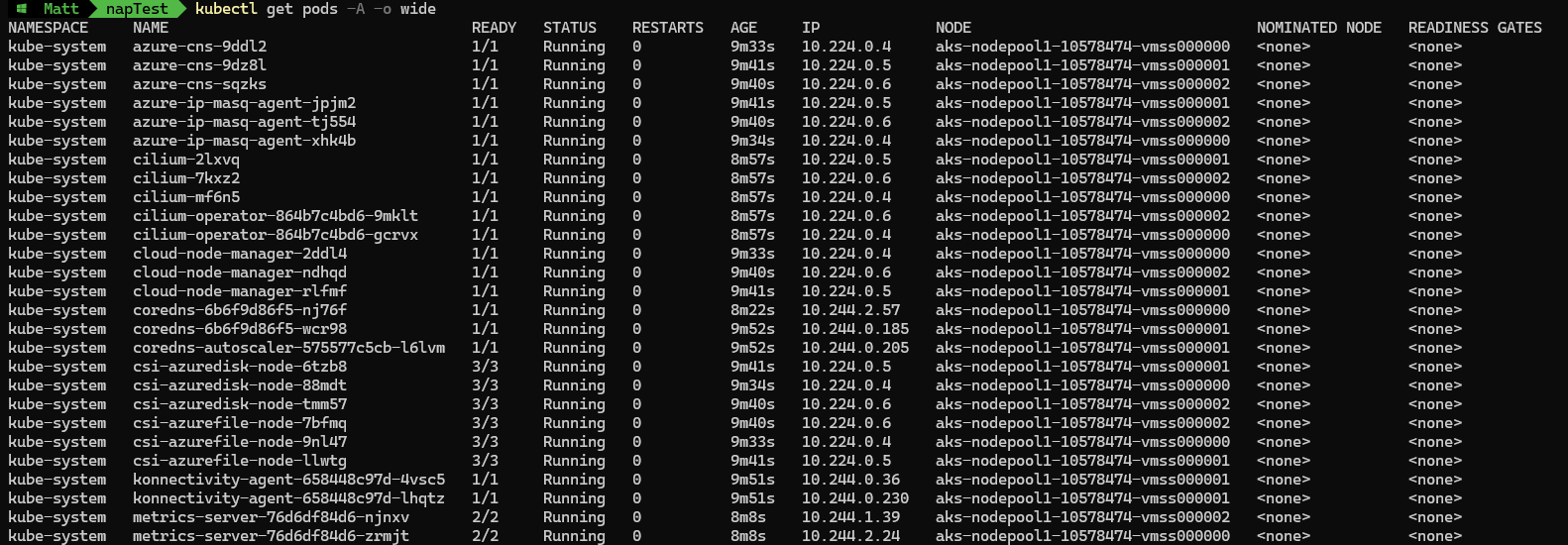
We can see the system node pool is running, with kube-system pods running across three nodes. We will now deploy a test nginx pod without any toleration for the system node pool.
Running a test nginx pod within the cluster:
kubectl run --image nginx nginx

Checking to see where the new pod is running:
kubectl get pods -o wide

After running the kubectl commnad to create a test nginx pod, we can see it is now in a pending state.
kubectl describe pod nginx

Describing the pod means we can see the events affecting the pod scheduling. Looking at the warning you can see no current nodes are available as they all have the CriticalAddonsOnly taint. After which the pod is nominated to a node pool by Karpenter rather than the default scheduler.
Rechecking node states with get nodes command:
kubectl get nodes -o wide

Rechecking node states with get pods command:
kubectl get pods -o wide

We can now see a 4th node online, and the nginx pod is now running on the newly created node.
Describe new node in more detail:
kubectl describe node <<NodeName>>
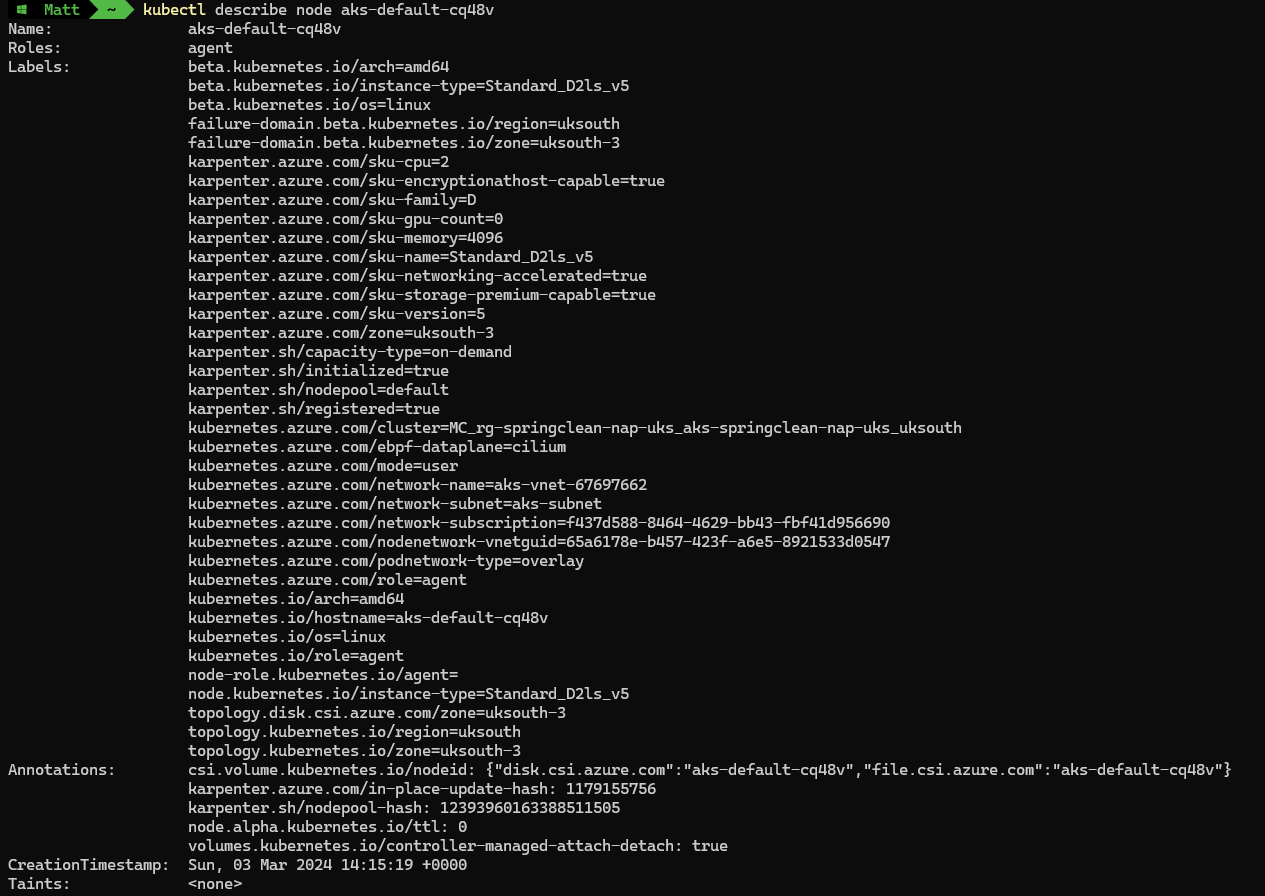
Looking at the fresh node, via the describe command. We can see a number of karpenter specific labels, these describe the configuration of the node, including information like sku-version, sku-family, sku-cpu and sku-memory
Cluster Updates
With NAP enabled AKS version upgrades are managed for you by default. NAP node pools stay in-line with the Control Plane Kubernetes Version, if the cluster is updated your NAP nodes are automatically updated to the same version.
By default, node images are also automatically updated when a new image becomes available.
Upgrading the control plane of the AKS cluster via the AZ CLI:
az aks upgrade --name aks-springclean-nap-uks `
--resource-group rg-springclean-nap-uks `
--control-plane-only `
--kubernetes-version 1.28.5
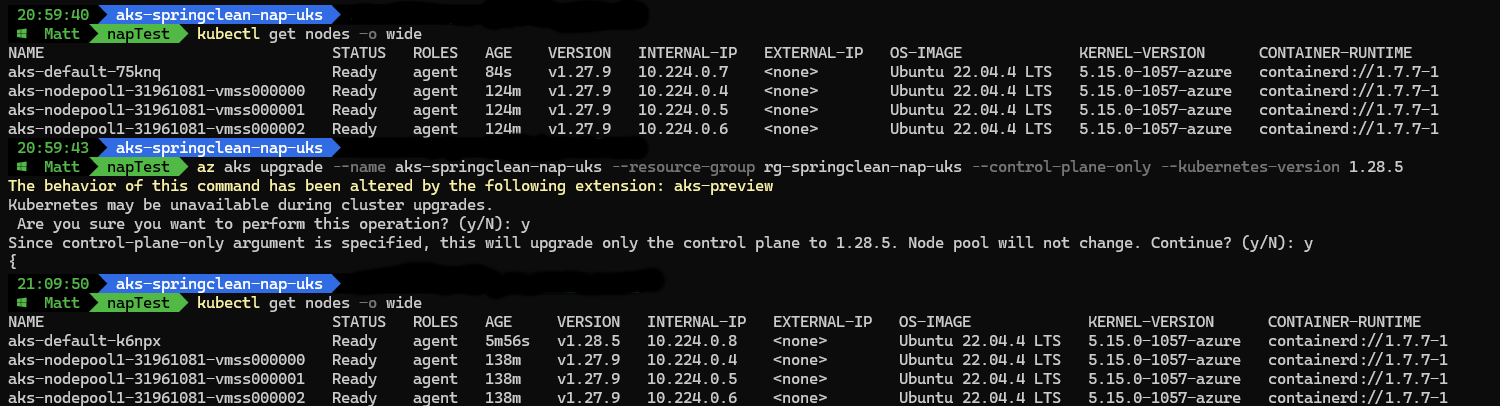
After the upgrade you can see the automatically updated NAP node running 1.28.5 as well, with the systemnode pool still waiting to be upgrading manually.
If required you can pin a node pool to a specific node image. This can be defined within the node class definition.
Getting aksnodeclass definition:
kubectl get aksnodeclass default -o yaml
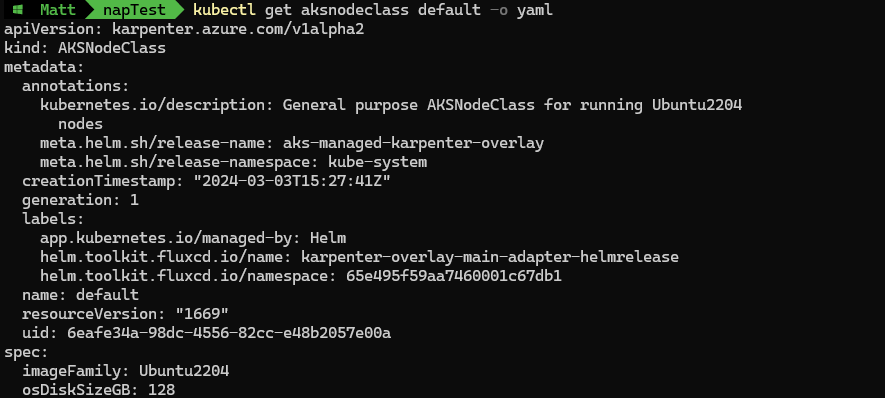
This is done by adding the imageVersion within the spec.
spec:
imageFamily: Ubuntu2204
imageVersion: 202311.07.0
osDiskSizeGB: 128
Node pool configuration
NAP uses a nodepool definition to assist with creating appropriate nodes for the pending workloads. This is also how you can ensure reserved instances are utilised. Additional definitions can be created but by default a default node pool definition is deployed by AKS.
View node poo; definition:
kubectl get NodePool default -o yaml
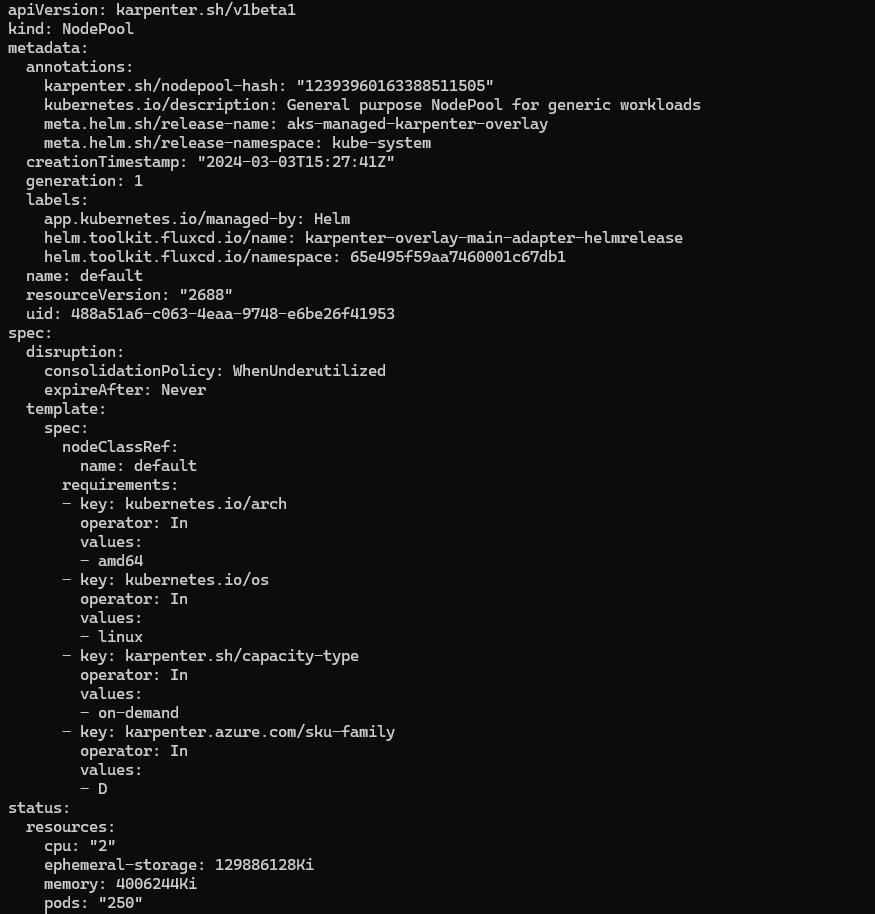
There are a variety of selectors that could be added to the definition to being addition control to the NAP node creation process.
| Selector | Description | Example |
|---|---|---|
| karpenter.azure.com/sku-family | VM SKU Family | D, F, L etc. |
| karpenter.azure.com/sku-name | Explicit SKU name | Standard_A1_v2 |
| karpenter.azure.com/sku-version | SKU version (without “v”, can use 1) | 1 , 2 |
| karpenter.sh/capacity-type | VM allocation type (Spot / On Demand) | spot or on-demand |
| karpenter.azure.com/sku-cpu | Number of CPUs in VM | 16 |
| karpenter.azure.com/sku-memory | Memory in VM in MiB | 131072 |
| karpenter.azure.com/sku-gpu-name | GPU name | A100 |
| karpenter.azure.com/sku-gpu-manufacturer | GPU manufacturer | nvidia |
| karpenter.azure.com/sku-gpu-count | GPU count per VM | 2 |
| karpenter.azure.com/sku-networking-accelerated | Whether the VM has accelerated networking | [true, false] |
| karpenter.azure.com/sku-storage-premium-capable | Whether the VM supports Premium IO storage | [true, false] |
| karpenter.azure.com/sku-storage-ephemeralos-maxsize | Size limit for the Ephemeral OS disk in Gb | 92 |
| topology.kubernetes.io/zone | The Availability Zone(s) | [uksouth-1,uksouth-2,uksouth-3] |
| kubernetes.io/os | Operating System (Linux only during preview) | linux |
| kubernetes.io/arch | CPU architecture (AMD64 or ARM64) | [amd64, arm64] |
Scaling Down
NAP can also use disruption rules to scale down Node Pools by removing nodes, or even rescheduling workloads for a more efficient configuration.
This configuration can be added to the nodepool definition under the disruption section.
disruption:
# Describes which types of Nodes NAP should consider for consolidation
consolidationPolicy: WhenUnderutilized | WhenEmpty
# 'WhenUnderutilized', NAP will consider all nodes for consolidation and attempt to remove or replace Nodes when it discovers that the Node is underutilized and could be changed to reduce cost
# `WhenEmpty`, NAP will only consider nodes for consolidation that contain no workload pods
# The amount of time NAP should wait after discovering a consolidation decision
# This value can currently only be set when the consolidationPolicy is 'WhenEmpty'
# You can choose to disable consolidation entirely by setting the string value 'Never'
consolidateAfter: 30s
I look forward to this feature coming out in GA and to have the possibility to optimise workload and node requirements. Therefore bringing an extra level of control to AKS cost management.